This is just an idea of mine - let me know what you think.
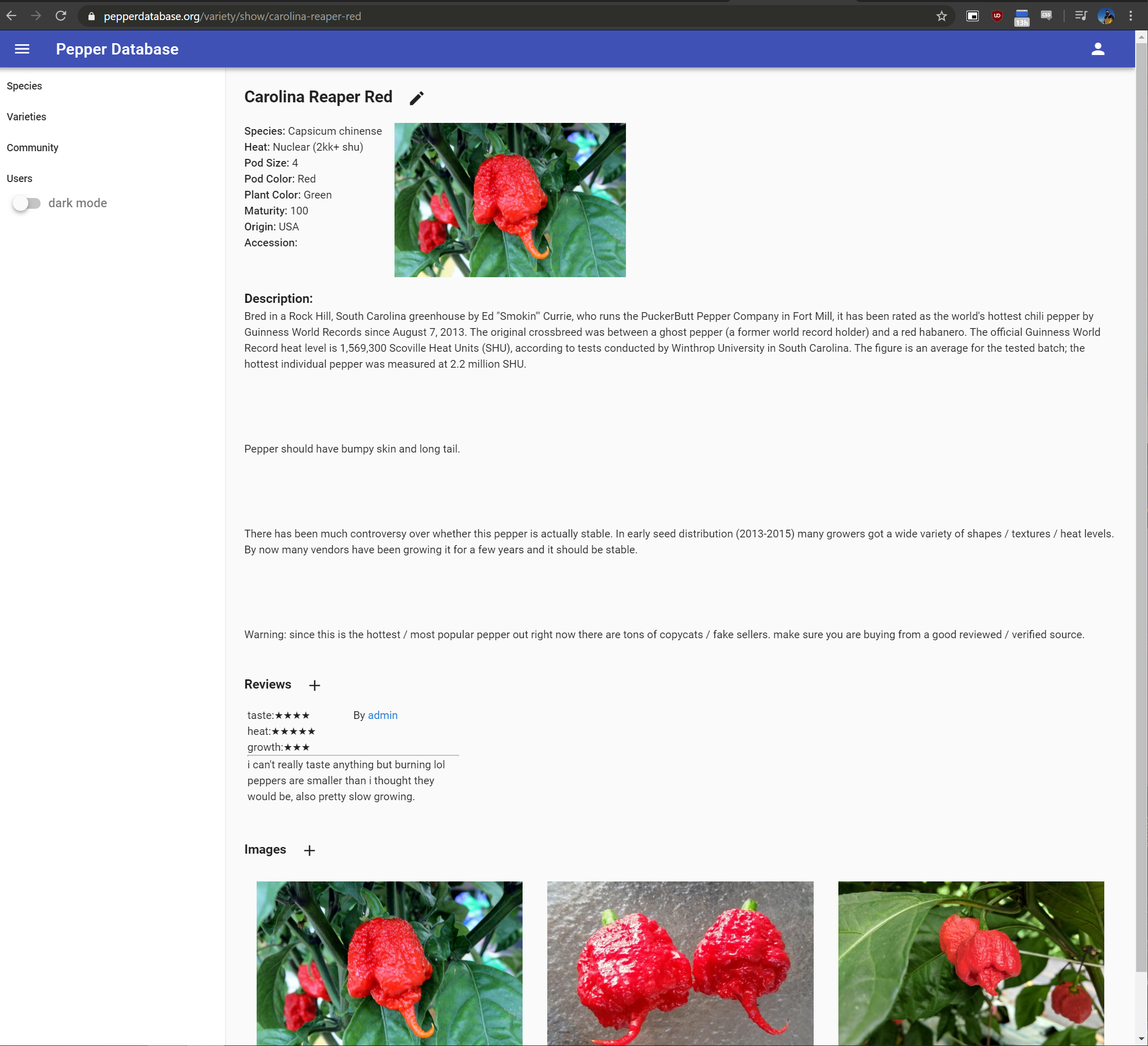
Pepper databases are cool, because there are so many varieties out there, and it's nice to have a way to keep track of them. It seems that there are a lot of different pepper lists and databases out there, but while they may have lots of info on individual plants, and even include rare varieties, none come even close to being unabridged. Now, I don't think that would be possible to have a "complete list" - there are far too many cultivars out there, and there will continue to be new ones. But I had an idea for a way to more comprehensively list the pepper varieties out there.
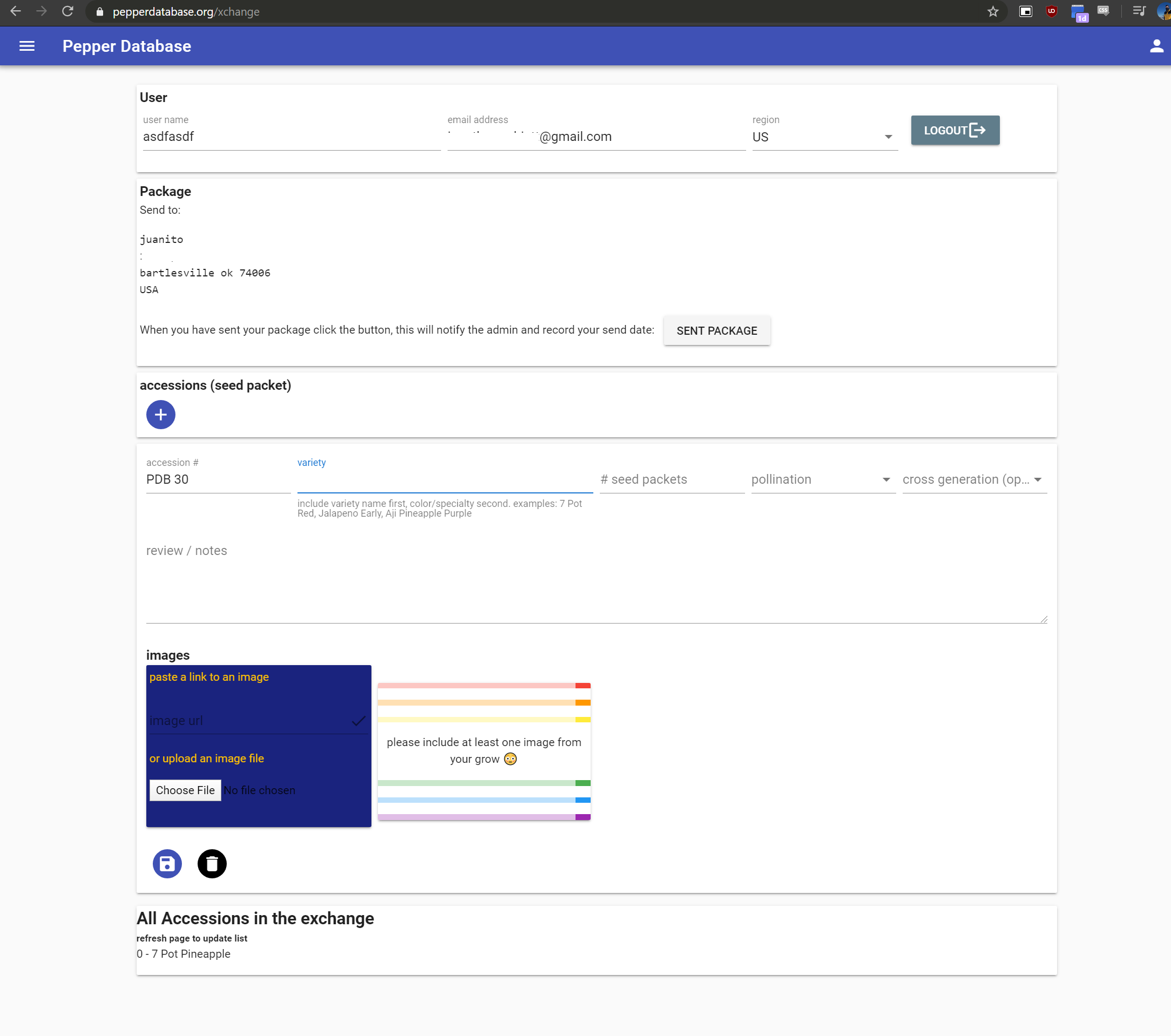
It seems like most databases on peppers out there try to have every bit of data possible: heat in SHUs, photos, growing tips, etc. Although these are useful, they take time to collect. I would like to, instead, make a database of pepper names. This may not sound like much, but it's one of the first things you need when you want to find info on a pepper - its name - and any other names/codes it goes by (alternate names, Its Christopher Phillips collection number, CGN number, etc.). The other two things I was thinking of including would be: minimal pod info (color, shape, size), and minimal genetic info (known related peppers, is it a named F1 hybrid (ex. super chili) or just a stable cultivar (ex. orange blob), and any known parentage). In this way, a relatively large database of peppers could be constructed, with minimal effort on a per-pepper basis.
The other aspect of this would be actually producing the database. I have some Access knowledge, and feel comfortable with learning a bit more SQL to get the job done with some SQL file-based system. One way I thought of, for filling out the database - at least as a start - would be to ask people to just enter the varieties they've grown themselves.
Any thoughts?
Best,
-'Pims'
Pepper databases are cool, because there are so many varieties out there, and it's nice to have a way to keep track of them. It seems that there are a lot of different pepper lists and databases out there, but while they may have lots of info on individual plants, and even include rare varieties, none come even close to being unabridged. Now, I don't think that would be possible to have a "complete list" - there are far too many cultivars out there, and there will continue to be new ones. But I had an idea for a way to more comprehensively list the pepper varieties out there.
It seems like most databases on peppers out there try to have every bit of data possible: heat in SHUs, photos, growing tips, etc. Although these are useful, they take time to collect. I would like to, instead, make a database of pepper names. This may not sound like much, but it's one of the first things you need when you want to find info on a pepper - its name - and any other names/codes it goes by (alternate names, Its Christopher Phillips collection number, CGN number, etc.). The other two things I was thinking of including would be: minimal pod info (color, shape, size), and minimal genetic info (known related peppers, is it a named F1 hybrid (ex. super chili) or just a stable cultivar (ex. orange blob), and any known parentage). In this way, a relatively large database of peppers could be constructed, with minimal effort on a per-pepper basis.
The other aspect of this would be actually producing the database. I have some Access knowledge, and feel comfortable with learning a bit more SQL to get the job done with some SQL file-based system. One way I thought of, for filling out the database - at least as a start - would be to ask people to just enter the varieties they've grown themselves.
Any thoughts?
Best,
-'Pims'